Pre-Training Step
- Language Model?—?A probability distribution over a sequence of tokens/words p(x1,x2,…,xn)p(x_1, x_2, dots, x_n)p(x1?,x2?,…,xn?). The model tries to identify grammatical mistakes and understand factual or semantic correctness, such as distinguishing between valid and invalid sentences (e.g., “The ground falls on the cat”).
- Generative Model?—?These models can generate text or audio. Language models are often referred to as generative models because, when trained on a probability distribution, they can sample from it to generate new data.
- Autoregressive Language Model?—?These models generate the next word based on the previous word, then continue generating the next word using the previous two words, and so on. Models such as RNNs and LSTMs follow this approach, but they are time-consuming for longer sequences.
1. Data Collection & Preparation
One example of leveraging internet crawl data for LLM pretraining is FineWeb. This dataset provides insights into the scale and type of data required for training large language models.
? FineWeb is a large-scale dataset for LLM pretraining, consisting of 15 trillion tokens and occupying 44TB of disk space. It is derived from 96 CommonCrawl snapshots and has been shown to outperform other open pretraining datasets.
How FineWeb Perform Data Cleaning steps:
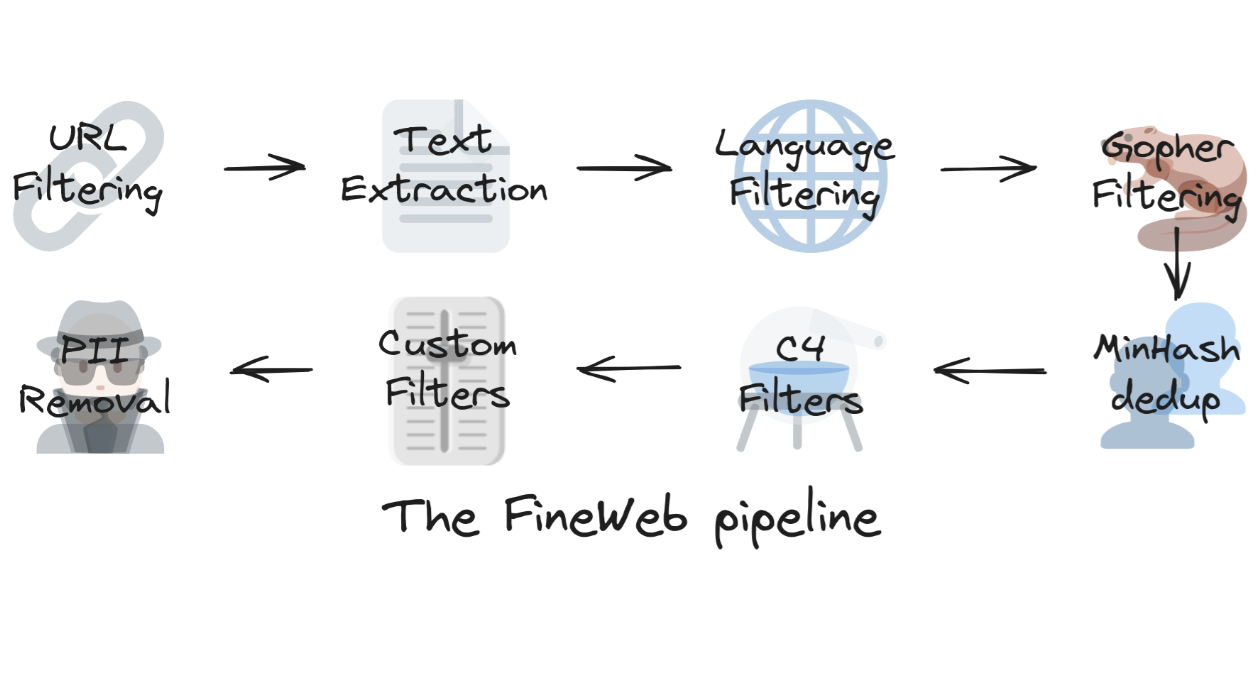
Key Preprocessing Steps for LLM Training
However, raw data alone is not enough?—?various steps and best practices are applied to prepare high-quality training data:
- Downloading Internet-Scale Data?—?Collecting large-scale text data from diverse sources.
- Text Extraction from HTML Pages?—?Stripping unnecessary HTML elements and retaining meaningful text.
- Deduplication?—?Removing redundant content across multiple web snapshots.
- Harmful Information Removal?—?Eliminating PII (Personally Identifiable Information) and sensitive data.
- Filtering Low-Quality Data?—?Removing low-token pages and discarding pages with excessively long gibberish text.
- Model-Based Classification?—?Identifying whether the content is derived from Wikipedia references or other trusted sources.
- Categorization & Domain Weighting?—?Classifying content into domains such as code, entertainment, books, or legal. Reweighting data based on training goals. For instance, if a dataset contains a high proportion of code and math, the model will develop stronger reasoning capabilities and behave accordingly.
Big competitors do not publicly disclose their exact data construction strategies or dataset sizes. However, based on rough estimates: LLaMA 2 (7B-65B)~1–2 trillion tokens, GPT-4~10+ trillion tokens and LLaMA 3~13 trillion tokens.
2. Tokenization
One straightforward approach to tokenization is treating each word as a token. However, this method has several drawbacks. First, typos can create entirely new tokens—for example, a small spelling mistake like "langauge" instead of "language" results in a different token, which reduces efficiency. Another issue arises with character-wise tokenization, where each character (e.g., "A", "B", etc.) is treated as a separate token. This approach loses semantic relationships between words, making it harder for models to understand context. Additionally, longer sequences increase computational complexity, leading to higher memory usage and slower training.
Byte-Pair Encoding (BPE): The Popular Tokenization Approach
BPE is an effective tokenization algorithm used by ChatGPT and other LLMs. It works as follows:
- Start with a large corpus of text.
- Initially, treat each character as an individual token.
- Iteratively merge the most frequent adjacent token pairs to form new tokens.
BPE Example: “large is large”
Step 1: Initial Character Tokens
['l', 'a', 'r', 'g', 'e', ' ', 'i', 's', ' ', 'l', 'a', 'r', 'g', 'e']
Step 2: Merging Frequent Pairs
Let’s say “l” + “a” → “la” is the most frequent pair:
['la', 'r', 'g', 'e', ' ', 'i', 's', ' ', 'la', 'r', 'g', 'e']
Then, “r” + “g” → “rg” is merged:
['la', 'rg', 'e', ' ', 'i', 's', ' ', 'la', 'rg', 'e']
Finally, “large” might be merged into a single token:
['large', ' ', 'i', 's', ' ', 'large']
Now, the phrase “large is large” is represented with fewer tokens, reducing computational complexity while maintaining context.
3. Base LLM Model
In the pretraining stage, the model learns to predict patterns in text by processing vast amounts of data. This phase establishes the foundational knowledge of the model, enabling it to generate coherent text, recognize linguistic structures, and understand semantic relationships.
What Does the Base Model Do?
At this stage, the model is a casual language model, meaning it learns to predict the next token in a sequence based on the preceding context. It does not yet have the ability to follow instructions, engage in dialogue, or act like an assistant.
Key Characteristics of the Base Model:
- Next-Token Prediction: Given a sequence of tokens, the model generates the most probable next token.
- No Instruction Following: The base model is not yet fine-tuned for structured responses or tasks.
- No Alignment with Human Intent: It lacks mechanisms like RLHF (Reinforcement Learning from Human Feedback) that make it more helpful and aligned with human preferences.
For example, if trained on causal language modeling, the base model might complete:
- "The sun rises in the..." → "east."
- "Machine learning is a branch of..." → "artificial intelligence."
However, at this stage, the model does not understand user intent, meaning it cannot effectively perform tasks like answering complex questions, following detailed instructions, or acting as a chatbot. These capabilities are developed in later stages, such as posttraining.
Post-Training:
After pretraining, the base model undergoes post-training to refine its abilities and make it more aligned with human expectations. This phase involves Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF).
1. Supervised Fine-Tuning (SFT)
? Goal: Teach the model task-specific skills and align responses with human instructions.
- In this step, the model is trained on high-quality, labeled datasets where human annotators provide input-output pairs.
- It helps the model follow instructions, generate structured responses, and improve task-specific performance.
- Example: If the model is given a prompt like "Explain quantum mechanics in simple terms", it learns to respond in a clear and concise manner.
- SFT is often done using human-curated datasets or expert demonstrations.
2. Reinforcement Learning from Human Feedback (RLHF)
? Goal: Optimize the model’s responses based on human preferences using a reward model (RM).
While SFT helps with basic instruction-following, RLHF refines responses using human feedback.
Reinforcement Learning (RL)
Reinforcement learning can be compared to studying from a textbook. In subjects like probability theory, textbooks provide worked-out solutions alongside practice problems at the end of each chapter. When solving these exercises, you already have a final solution to compare against.
In RL, the model is given a problem and iterates multiple times to discover the optimal solution. The key point is that we have concrete answers, so the system can check its performance automatically without human involvement.
RLHF comes into play when tasks don’t have a single correct answer, such as: Summarizing news articles, Writing a poem or Generating creative responses
Since these tasks involve subjective evaluation, traditional RL approaches fail. It’s impractical to have humans manually rate thousands of model responses. Instead, we create a Reward Model (RM) using a neural network to simulate human preference evaluation.
Key Components:
- Policy Model (π): The fine-tuned LLM from SFT.
- Reward Model (R): A separate model trained to rank responses based on human preferences.
- Proximal Policy Optimization (PPO): Used to update the policy based on RM scores.
? RLHF Process:
Collect human preference data:
- Show annotators multiple responses from the fine-tuned model.
- They rank responses from best to worst.
Train the Reward Model (RM):
- Use the ranked responses to train a reward model (typically a BERT-style model).
- The RM learns to assign higher scores to better responses.
- Over time, the reward model becomes a better simulator of human judgment, reducing human effort.
- Loss: Pairwise Ranking Loss (Bradley-Terry model or Margin Loss).
Optimize the policy model using RL (PPO):
- The LLM model generates responses.
- RM scores each response.
- The model is rewarded or penalized using PPO.
- Loss: PPO Loss (policy gradient update) to balance exploration vs exploitation.
- Iteration & Fine-Tuning – The process is repeated, ensuring the model provides helpful, safe, and coherent responses.
This approach enables large-scale reinforcement learning while keeping human involvement minimal.
For a deeper dive, refer to the paper: Fine-Tuning Language Models from Human Preferences
Loss Functions
Training large language models (LLMs) involves multiple stages, each with its own optimization objectives. Below is a breakdown of the key loss functions used in Pretraining, Supervised Fine-tuning (SFT), and Reinforcement Learning with Human Feedback (RLHF).
1. Pretraining Loss (Cross-Entropy Loss)
Objective:
Train the model to predict the next token given previous tokens, using vast amounts of unlabeled text data.
Loss Function:
LPretraining?=−t=1∑N?logP(yt???x1?,x2?,...,xt−1?)
Where:
- yt? is the actual token at position t.
- P(yt???x1?,x2?,...,xt−1?) is the predicted probability of the token.
- The loss is summed over all tokens in the dataset.
Explanation:
- This is a causal language modeling (CLM) loss used in decoder-only models like GPT.
- It ensures that the model learns probabilistic word distributions based on training text.
2. Supervised Fine-Tuning (SFT) Loss (Cross-Entropy Loss)
Objective:
Fine-tune the pretrained model on a labeled dataset where human-curated responses are provided.
Loss Function:
LSFT?=−t=1∑N?logP(ytcorrect???x1?,x2?,...,xt−1?)
Where:
- ytcorrect? is the ground-truth token at step t.
- Similar to pretraining, but now trained on high-quality, human-annotated data instead of raw internet text.
Explanation:
- The model is refined to generate responses that align with human intent.
- Improves model behavior before reinforcement learning.
3. Reward Model Training Loss (Pairwise Ranking Loss)
Objective:
Train a reward model to rank responses based on human preferences.
Loss Function:
LRM?=−logσ(R(x,y+)−R(x,y−))
Where:
- R(x,y+) = Reward score for the preferred response.
- R(x,y−) = Reward score for the less preferred response.
- σ = Sigmoid function, which squashes the difference between rewards into a probability.
Explanation:
- The reward model (RM) learns to assign higher scores to better responses.
- The loss encourages the model to maximize the separation between good and bad responses.
4. Reinforcement Learning with Human Feedback (RLHF) Loss (PPO Loss)
Objective:
Use reinforcement learning to further align the model's behavior based on human feedback.
Loss Function (PPO):
LPPO?=min(πold?(y??x)π(y??x)?A,clip(πold?(y??x)π(y??x)?,1−?,1+?)A)
Where:
- π(y??x) = Current policy (new model probabilities).
- πold?(y??x) = Old policy (previous model before the update).
- A = Advantage function, which measures whether an action is better than expected.
- ? = Clipping parameter, ensuring stable updates.
Explanation:
- Policy loss ensures the model maximizes rewards assigned by the RM.
- KL penalty prevents excessive divergence from the fine-tuned model.
- Uses Proximal Policy Optimization (PPO) to stabilize updates.
Summary:
Pretraining
- Language Models: Predict the next word based on context.
- Data Collection: Internet-scale datasets like FineWeb (15T tokens, 44TB).
- Preprocessing: Deduplication, PII removal, low-quality filtering, domain weighting.
- Tokenization: Byte-Pair Encoding (BPE) improves efficiency by merging frequent token pairs.
- Base Model: Trained for next-token prediction but lacks task-specific understanding.
Post-Training
- Supervised Fine-Tuning (SFT): Aligns responses with human instructions using curated datasets.
- Reinforcement Learning from Human Feedback (RLHF): Optimizes responses with a Reward Model (RM) and Proximal Policy Optimization (PPO).
- Loss Functions: Pretraining uses Cross-Entropy Loss, SFT minimizes task-specific loss, and RLHF applies Pairwise Ranking Loss & PPO Loss.
Tags: llm, GenAI, NLP, RHFL, Tokenization



